With a boost in numbers on vocab.oxlos.org, this post looks at some slightly more detailed statistics from the first activity.
Just 5 days ago there were 82 sign ups with 52 people having completed the first activity. Now there have been a total of 116 signups and 79 people have done at least the first activity (with 44 having done more than one). Thank you very much everyone!
In my last post we looked at mean item difficulty (what proportion of people get an item correct) by frequency bucket.
We saw that the coarse frequency buckets had an okay correlation with item difficulty but not great. We’ll explore that a little more in the near future but in this post I want to introduce another dimension: the ability of the person being asked the item.
I should note that in psychometrics (and in item response theory in particular, which we’ll be getting to) the term "ability" is used in a specific sense of the measurement we’re trying to take of the person (with no assumption of whether it’s innate or even desirable). It’s just the person-specific construct we’re trying to measure.
As an initial proxy for this "ability" in the context of the first activity on the site, I’ve used the total percentage of items in that activity answered correctly by a given person. This is just the raw percentage of items answered correctly, not quite the same as the estimate of NT vocabulary coverage shown on the site. This raw percentage is then used to group people into buckets (just in the context of the first activity for now).
Now we can tabulate item frequency buckets vs person ability buckets with the following result:
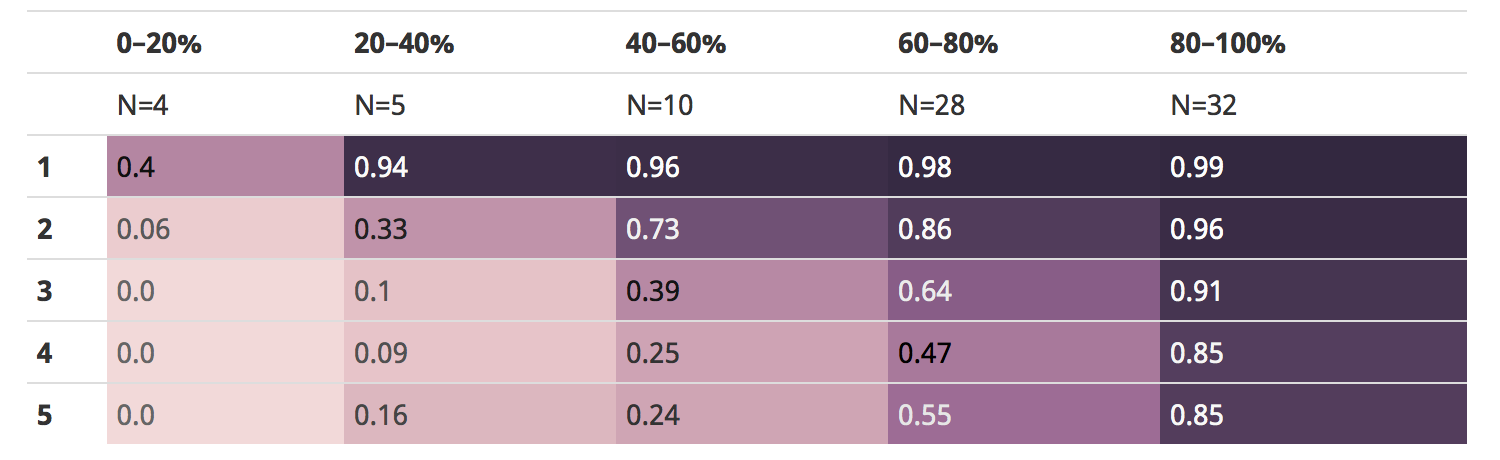
First off, you can see we’re still somewhat lacking in numbers of people of beginning-intermediate ability.
But importantly, you can see how mean item difficulty (the number in each cell) varies by ability bucket (the column). We’ve already seen that mean item difficulty isn’t a great predicator of item frequency bucket. Splitting out different abilities like we do above makes discrimination easier in some cases. But the important thing to note in the table above is that the mean item difficulty WITHIN a frequency bucket (row) is a good indicator of a person’s overall ability bucket.
This is less the case in the bucket for the most frequent items (the row labeled 1), which makes ability buckets 20% and above difficult to discriminate. Similarly, the less frequent item buckets aren’t as good at discriminating between the lower ability buckets. This is what we would expect.
But overall, frequency buckets 2 through 5 (and especially 3 and 4) do an excellent job of discriminating each of the ability buckets above 20%. 5 seems particularly well suited for each of the buckets at 40% ability and above and 1 only really between the 0–20% bucket and the rest.
I suspect it’s going to be interesting to have more fine-grained item frequencies but even MORE interesting to put aside frequency all together and bucket them by overall difficulty. I’ll do that in a subsequent post once I’ve done the analysis. At some point I’ll also look at individual items and their ability to discriminate ability.
For now, though, I did want to share a finer-grained bucketing of ability, with ten buckets instead of five:
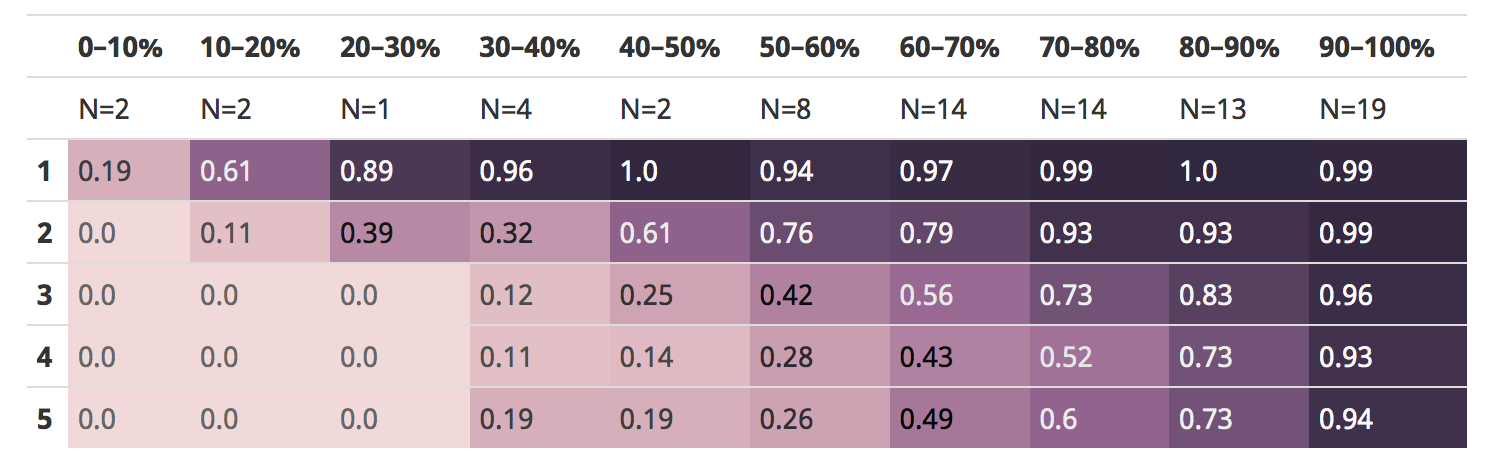
The lack of people below the 50% ability mark makes this a little less useful and there are adjacent ability buckets that cease to be discriminating at this level of granularity.
But the important pattern is still there, assuming for now frequency is a proxy for difficulty: if an item is easy, it can’t discriminate people of higher ability, although may be great at discriminating those of lower ability; and if an item is hard, it can’t discriminate people of lower ability, although may be great at discriminating those of higher ability.