I recently saw a nice visualisation of English letter bigram frequencies and decided to replicate it with Greek New Testament data.
You can see the English original in this post on All Things Linguistic. That's not where I originally saw it, though. I think I saw a link on Twitter to a Reddit post.
I wrote a quick Python script to generate the same style of visualisation based on word types (not tokens) in the SBLGNT after stripping accents and folding to lowercase (but keeping the apostrophe used to mark elision). This is the result:
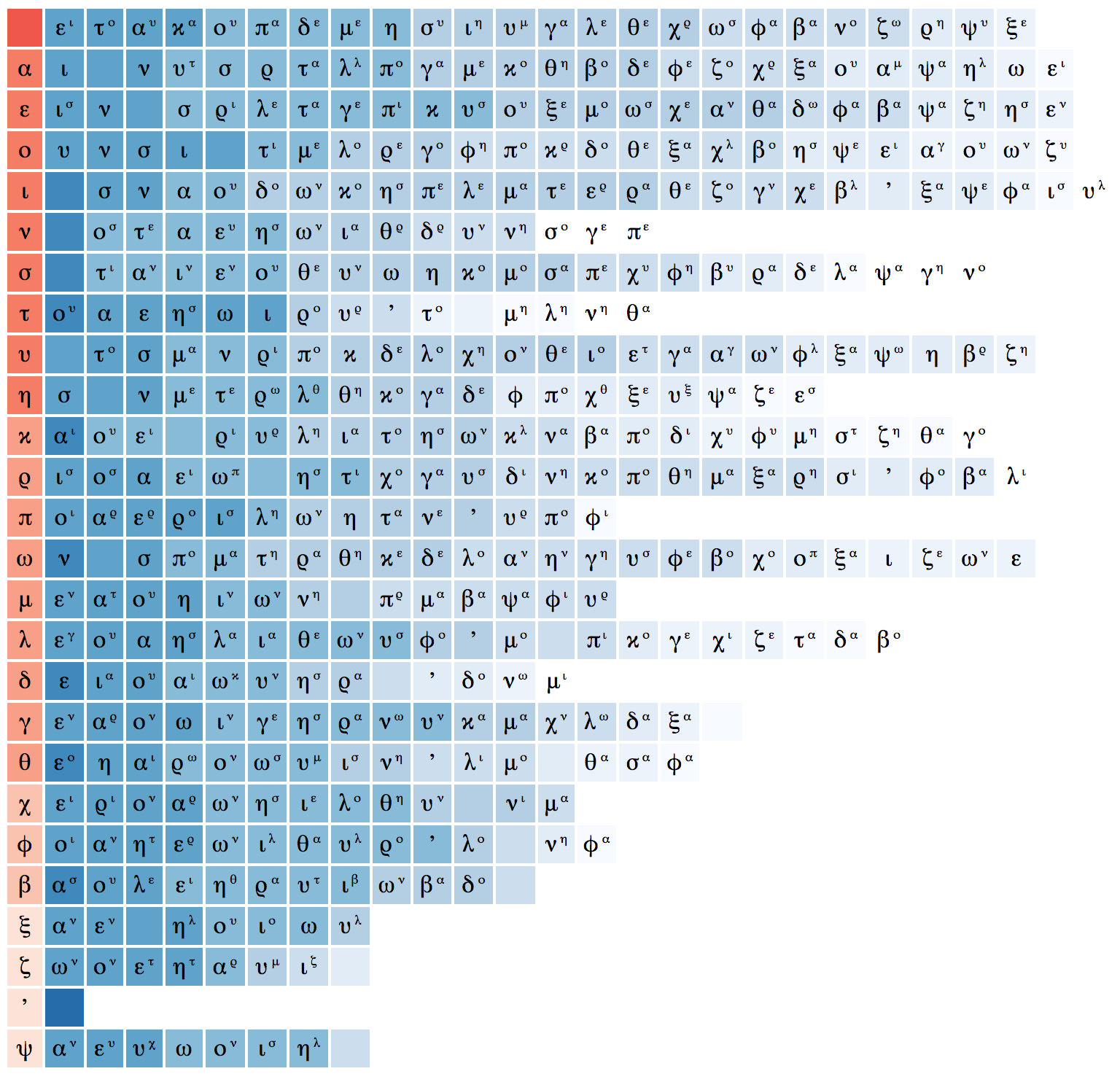
The intensity of red in the left column indicates the relative frequency of that letter overall. Each row then indicates (via ordering and the intensity of blue) the relative frequencies of what letter follows that red letter. The superscript then indicates the single most likely letter to follow that sequence of two letters. So it shows all unigram frequencies, all bigram frequencies, and the most common trigram for each bigram.
I also used the same bigram and trigram data to generate pseudowords, much like the English original did. At the time, I only tweeted about this second part.
Trigram-based generation of Greek-like words seems promising: ὀκρός θρωτοί δελθομοῦς ἐδωσῖνα ἐπιδάς εὑόν εἰπῆς ἐνησόφος πόδου δόξηλθον μετέ
— James Tauber (@jtauber) August 7, 2017
Patrick Burns asked me for the pseudword generation code so I extracted it, cleaned it up a bit and posted it to a gist here.
I never got around to posting my letter frequency visualisation, but Seumas Macdonald (not knowing I'd already done the work) pointed me to the All Things Linguistic blog post and asked about the possibility of doing the same for Greek. It was enough of a nudge to get this blog post written.
Thanks Seumas and Patrick!