I was thinking about vocabulary differences between books of the New Testament and decided to see what happens when you do a hierarchical clustering analysis of NT books using the Jaccard distance of their lemma sets.
This is some old-school stylometry but the results are still pretty interesting. For each book, I calculated the set of lemmas and then, for each pair of books, calculated the Jaccard coefficient (the ratio of the intersection of the sets and the unions of the sets).
I then did a cluster analysis using Ward's criterion and rendered the results as a dendrogram:
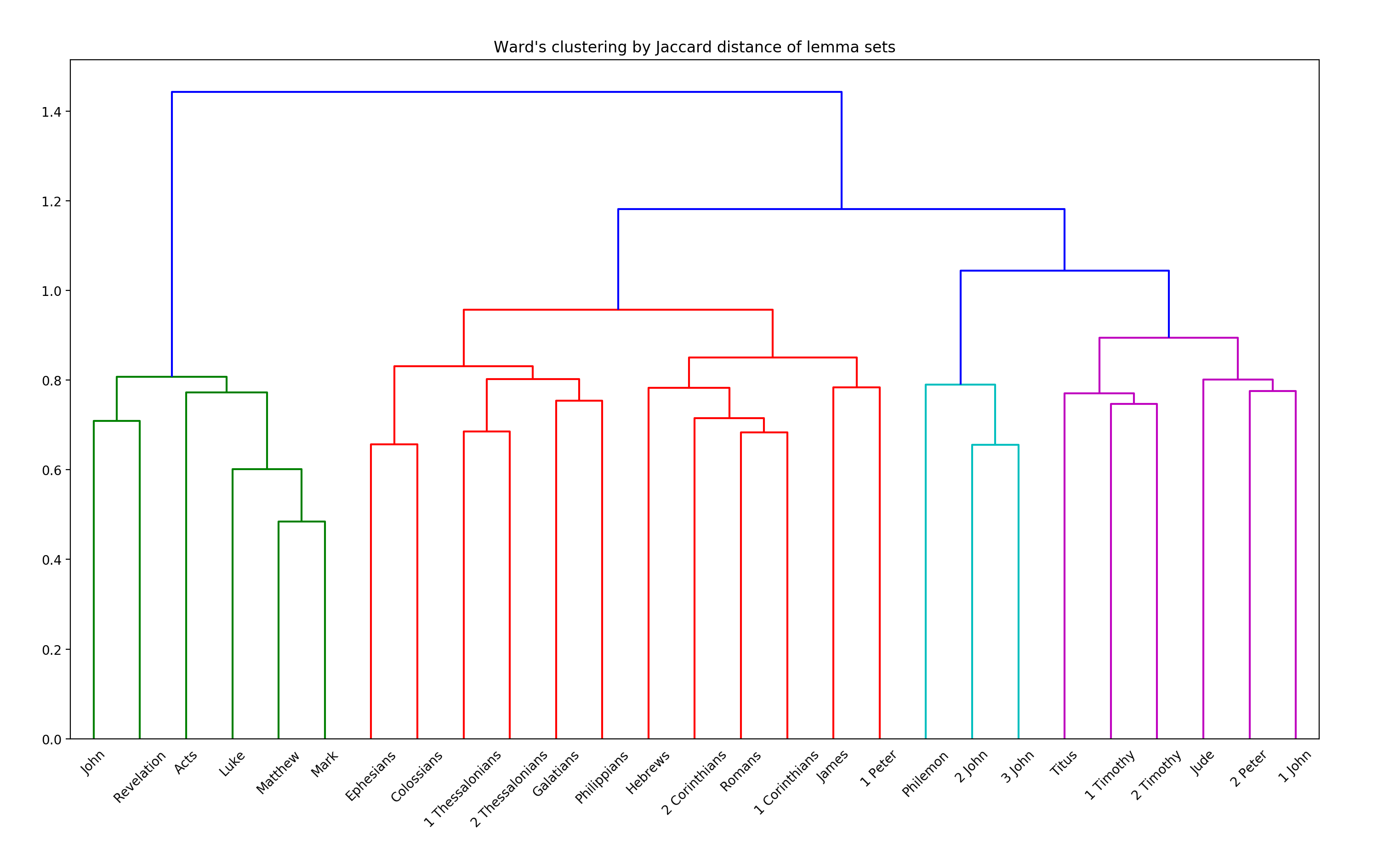
Notice that the first split is between the letters and non-letters.
Within the non-letters, John's Gospel and Revelation cluster together as do Acts and the Synoptics. The Synoptics cluster with each other more than they do with Acts. Matthew and Mark cluster together more than they do with Luke.
The highest division in the letters is between:
- the non-pastoral Pauline epistles plus Hebrews, James and 1 Peter
- the pastorals plus the rest of the general epistles (2 Peter, the Johannine epistles and Jude)
That first division of letters further clusters into:
- Galatians, Ephesians, Philippians, Colossians, 1 Thessalonians, 2 Thessalonians
- Romans, 1 Corinthians, 2 Corinthians, Hebrews, James and 1 Peter
Ephesians and Colossians cluster together, the two epistles to the Thessalonians cluster together, and Galatians and Philippians cluster together.
Romans, 1 Corinthians, and 2 Corinthians cluster (although 1 Corinthians clusters closer to Romans than to 2 Corinthians). James and 1 Peter cluster. Hebrews is in the same overall group but clusters closer to the Romans/Corinthian subgroup.
The second division of letters clusters into:
- Philemon, 2 John, 3 John
- Titus, 1 Timothy, 2 Timothy
- Jude, 1 John, 2 Peter
with the second and third clustering slightly closer than the first.
2 John and 3 John cluster much closer to each other than to Philemon. The epistles to Timothy cluster slightly closer together than they do to Titus. 1 John and 2 Peter cluster slightly closer together than they do with Jude.
I haven't thought about length effects here but they may influence the clustering of very short books together (and possibly very long books). A lot of the clustering does follow similar lengths so it's definitely worth thinking more about.
Of course, there's nothing new about this kind of analysis. As I said at the start, it's old school—the sort of thing I can imagine being published in a "humanities computing" journal in the 80s. But it's still interesting. And it might be even more interesting to apply to finer-grained text divisions and/or with properties other than lemmas.